Xrefs: Problem | Scoreboard | Codeforces announcement, this blog | Hacker News
Team: cat /dev/random | grep "to be or not to be"
Who: Jan-Willem Buurlage, Ragnar Groot Koerkamp, Timon Knigge, Abe Wits
Score: 10282641
Rank: 16
Since we did quite well, here is a write-up of our participation in Hashcode 2021.
Prep Link to heading
All four of us had previously participated in Hashcode, but this was the
first time in the current composition. Since we estimated our chances of
getting through to the finals to be more than nothing, we decided to
practice some previous Hashcode problems. Not all test sessions were
equally successful, but we did manage to get a good division of work:
while I start by immediately writing the IO Input and Output
classes, and the Output::score() function, the others always start
with reading the statement, analysing the testcases, and writing at
least one greedy solution. This already is a big step up from previous
years/teams, where usually everybody would write the IO themselves.
Next to this, we also set up a template repository (to be open-sourced
eventually) containing stub io.h and main.cpp files. This way, all
we have to do is store, read, and write the Input and Output, while
the API is already fixed so that others can start writing their parts
without waiting for me to be done with the basics.
Another great help is a custom run.py script that compiles a solution
and runs it on all testcases, stores all solution files, and keeps
track of maximum scores per testcase so far. To ease online submission,
it symlinks these best scores to a separate directory, where it also
writes the zipped code. After post contest optimizations, the output
looks like this:
| |
We also have a small Python script to help with analysing the testcases, containing some functions to quickly print a summary of a list of numbers so it’s easy to quickly get a feeling for e.g. the range of in-degrees in this problem.
Progress Link to heading
With an early break from work, a quick outside walk, plenty of coffee, food, and snacks stashed, the git template copied, and some final jumping jacks done, we were ready for the start!
This sections covers all the mistakes we made - the interesting stuff comes after.
First hour Link to heading
| |
Help! The site didn’t load for most of us, so committing the pdf and input (as we do anyway) turned out to be the faster option. (Note: Times are relative to the contest start.)
| |
While the others started reading the long statement, I wrote the reading of the input and writing of the output. (I won’t explain the problem here, you probably already read it anyway.) Input was relatively simple, but required a rewrite to directly map street names back to integers. That probably took most of those 11 minutes:
Input data
| |
Output took slightly longer, mostly because this requires both writing and reading, so we can improve existing solutions using local search. One nice thing here is that the problem statement has a sample input and output, so now we can do a sanity check and read and write the output, and check whether it remains the same.
Output data
| |
| |
Next up was adding the scoring function, which took considerable time.
This problem had relatively complicated simulation with lots of
bookkeeping and different ids, which made it slow to implement this
correctly. I opted for a simple yet slow approach as initial
implementation: For each time step, iterate over all streets and check
whether the traffic light is green using std::map::lower_bound. Each
street would have a queue of cars waiting there. This can be improved in
multiple ways, but I figured having an implementation fast was more
important than having a fast implementation.
In the end I got the right score on the sample output, and without submissions to test the scoring function, I was happy and continued to write a simple solution myself.
Everybody gets 1 Link to heading
| |
The simplest idea I could come up with was the following: for each intersection, give 1 second of green light to each incoming street. We do not yet care about the order, so just order them as they appear in the input.
Given all the work done before, coding this was very simple:
A simple idea
| |
I ran this on all the testcases and made our first submission to the judge system for a total of 7,885,741 points. A decent score with a position somewhere in the top 1000 IIRC, but nowhere close to top 100. We had spent a lot of time on IO and scoring already so this is not too surprising for a very simple first attempt.
This is the point where we learned the judge actually has some great visualizations and info to help debugging. If only we’d known before!
Playing around a bit, I was able to increase the score on F by 300k by making a light green for \(x\) seconds when a total of \(x\) cars entered via that street. The intuition as for why this may be a good idea should be obvious.
A diff of 300k
| |
Fiddling a bit more, I was able to bump F another 500k as well by making it green for \(\sqrt x\) seconds. At the time, this seemed sensible, \(\sqrt x\) being the geometric mean of \(1\) and \(x\), but I didn’t really have a proper explanation.
A diff of 500k
| |
| |
Somewhere along the way, the introduction of the
if(usage[sid] == 0) continue, i.e. only giving green lights to streets
that are used at all, in combination with the original 1 second
duration, bumped the score for D another 600k.
At this point, we were in the 9.4M-9.6M range. Very respectable, but not yet in the top.
A greedy approach Link to heading
| |
Meanwhile, Jan-Willem was working on a greedy solution, and Abe and Timon were trying to analyse the testcases, but having a somewhat hard time because the it seemed like the testcases did not contain much structure that could lead to simple greedy algorithms.
Jan-Willem was trying the following simple greedy idea: for each traffic light, change the green light when the queue for a not yet used light becomes longer than the queue for the current light. Like the scoring function, this required a lot of debugging to get working.
After some time, it turned out two of the issues were actually in my scoring function. The first I had already fixed: the green light function broke on intersections without a schedule assigned.
| |
Secondly, the outputs made by his greedy solution weren’t accepted by
the judge system. It turns out my hope that the online judge would
ignore intersections with 0 assigned green lights, but alas, that’s not
the case. This required a small rewrite of the Output::write()
function, first counting the number of intersections with any assignment
at all, and only then looping over them to print the schedules.
The score log gets a bit messy here, but it seems that this solution managed to bump A to the 2002 optimum, and it gained another 6k points on E.
During all this, Timon was writing a dedicated solution for C, in total gaining another 65k points.
Bugs everywhere Link to heading
But that was only the beginning of the scoring woes…
The local scores for my simple solution above were this:
| |
But wait?! This gives 0 points for D while the online judge gave us close to 1M points… I think Timon was already looking at the code while I was writing my previous solution. He actually did spot a bug: I had mixed two different indexes and used the number of streets already done by a car as the global street id, instead of looking this up in the list of streets for the car first.
| |
Fix bad index
| |
With that fix out of the way, problems weren’t gone though. At this
point I was quite confused and thinking something must be wrong with the
way we compute this end_t: the time of reaching the end of the next
street. In particular the if statement above didn’t seem right. That
took another half hour of thinking/trying/coding, and then finally, two
and a half hours into the contest, the score() function was finally
working.
At this time I spent some time cleaning our solutions directory, since all those solutions had bad scores attached to them and were potentially going to hide better solutions.
Lucky ride Link to heading
Somewhere after fixing the scoring function, I was thinking what I should do next. The previous idea of handing everyone some duration of green based on the usage was nice, but not actually greedy. Instead, I wanted to assign green lights at exactly the right times. However, the problem in doing this is that you can only do this efficiently if you know the modulus (i.e. the total time of the schedule) of an intersection in advance. From previous experience, making simplifying assumptions until the point where implementation is easy is often a good idea, so here’s what I did:
Let’s just say that we’re going to give exactly 1 second of green light to each incoming car, as we did before. Now this fixes the modulo \(m\) for the traffic light. The natural greedy choice now becomes: whenever a car arrives at an intersection, make that traffic light green as soon as possible, given that this street hasn’t been assigned yet in the schedule.
Looking back, this idea actually follows very naturally from the non-greedy variant which already scored great points, but in practice, they were completely independent - I was just looking to fix the modulus and the duration of 1 for each light was automatically implied by this.
Greedy
| |
It took roughly half an hour to implement this, and the result was nice: +190k on D. However, that still left a significant ~1M gap to the leaders, so clearly we were missing something.
I played around a bit with my code, thinking maybe it’s better to give
each car a little bit of ‘slack’, and make them wait one extra second
before claiming the green light. Boom! +640k just by adding ++t at
the start of make_next_green and an unconditional return false; in
free_green. Completely out of nowhere. I think this is were we got
really lucky, as this is what got us our top 30 position. (More on this
later.)
After trying some more things, adding another ++t, adding it only with
some conditions, adding it in other places, I couldn’t actually improve
this further.
Other things we tried (Jan-Willem gave up his greedy and tried modifying mine) were sorting the streets around each intersection in different ways (longest queue, earliest arrival, longest route to go, …) but none of this improved the original situation. (Most likely, I ‘broke’ the lucky high scoring code in the stress of the final half hour, and all our further changes were never going to be as good as the original anymore.)
Local Search Link to heading
In the end we were able to gain another roughly 10k points by running two local search algorithms on the input. Abe had mostly been working on these, and was joined by Timon eventually.
Since updating the score function for local increments is rather
difficult in this problem, we just reran the score function after each
mutation. The two mutations we used were: * random_shuffle the order
of green lights * Add/remove 1 to the duration of a traffic light. *
Take a traffic light with duration at least 2, decrement it by 1, and
add this 1 somewhere else.
Sadly again there were occasional crashes here due to a
% intersection.green.size(), which could be 0 in some solutions. We
quickly identified this after the contest, but missed it in the stress
of it all.
The slow score function also didn’t help - it wasn’t hard to speed it up from up to 5 seconds to something 10x faster, but we didn’t get to it during the contest.
Post contest clarity Link to heading
So, where did that 640k on D come from? Turns out that actually, I had a
bug in my code: free_green would always return true when the current
time slot isn’t assigned yet, but in practice, the current street may
already be assigned to another time slot. This would make free_green
return true, but make_next_green would actually fail because the
street had already been assigned to another timeslot. Then, the
simulation starts running out of sync with the solution it’s building,
making for a much lower than expected score. Adding the return false
fixes this by just never going through this code path in the first
place, so now at least the solution is simulated correctly.
But now consider we’re at time t and the current slot t%m is not yet
assigned. The code would go to make_next_green so claim a slow as soon
as possible (after now), but instead of claiming some t' > t, it would
actually claim t itself. Thus, we have to wait m-1 turns now! Very
suboptimal. The extra ++t accidentally fixed this and made it claim
the first point in time after the current time, giving a solution much
closer to what I actually had in mind.
After the contest, when I actually added the proper check to
free_green instead, the score went up by another 80k.
For testcase F, playing around some more I found out that \(\sqrt{0.1\cdot x}\) actually also bumped the score by another 80k, and I was told about sorting the durations by decreasing length, which gave another 30k.
Improving the local search also gained another 10k on F, and maybe
somewhere around 20k-30k in total. It turned out that the scoring
function speed-up only took 5 minutes to implement, which would have
saved valuable waiting time during the contest. A further improvement to
the local search was to merge the binaries with different mutations into
one, so that all of them could be applied in turns, and adding a
#pragma omp parallel for around the main loop to speed things up by
another factor. This will definitely make it to our new local search
template.
Results Link to heading
Our final scores are as follows:
| problem | contest | extended round |
|---|---|---|
| A | 2,002 | 2,002 |
| B | 4,568,231 | 4,568,807 |
| C | 1,305,017 | 1,312,204 |
| D | 2,405,226 | 2,493,047 |
| E | 708,005 | 718,417 |
| F | 1,294,160 | 1,419,782 |
| total | 10,282,641 | 10,514,259 |
| rank | 16 | 15 |
Takeaways Link to heading
In general, we had too many bugs, everywhere. Next time we may do some pair programming or more review of complicated scoring code to prevent spending hours and hours bughunting.
Usually problems benefit from a case by case analysis and we’ll definitely keep on doing that, but this time it just didn’t help so much, or maybe we just didn’t find the right things to look at.
Abe spent most of his time on local search. This did get some 10k-20k points in the end, but that’s nothing compared to the missing O(100k) in both D and F. Next time we’ll have a local search library ready so that we can start this in the background with only minimal intervention. Then we can focus on parameter search instead, since that actually seems much more promising.
In general, this contest really only needed one insight above the ~9.5M baseline of just assigning each traffic light some fixed time. To get to the top 20, all you needed was a correct implementation of this idea to greedily pick time slots given a fixed modulus per intersection. Our implementation had bugs, but had it not, we would have been 12th instead of 16th.
The analysis on B and C didn’t give a lot of results, and in retrospect this wasn’t needed anyway - our greedy solutions were already very close to the theoretical maximum (which we forgot to compute during the contest). If we had known that, we could have spent our time elsewhere.
E did have a very clear structure, but we weren’t able to exploit this in any useful way. But anyway it seems that we got a close to optimal score here.
So that leaves D and F, where most incremental points were obtained, but where we didn’t have any understanding of what was going on.
Because of the lack of the potential to manually solve testcases, my feeling is that this contest was a bit low on creativity and a bit higher on luck (although multiple, but not many, teams seem to have found the solution to D from actual analysis).
Some more analysis Link to heading
I’m planning to write some more maths on the following problem:
Given that cars come in from \(k\) streets, with \(0 < c_i\leq 1\) cars per second coming from street \(0\leq i < k\). Assume all cars come at uniform and independent points in time, what is the optimal traffic light schedule?
The first result I already have: Given \(k=2\) and \(c_0 < c_1\). If we set the light for the first street to green for \(t_0=1\) second, the optimal duration for the second green light should be
\begin{equation} t_1 = \frac1{c_0} \left(-1 + \sqrt{1 + 2c_0c_1-c_0^2}\right). \end{equation}
When \(c_0=1\), this simplifies to \(-1 + \sqrt{2 c_1}\), which actually isn’t that far off of the \(\sqrt{x}\) guess we made before!
In case you have ideas here (maybe you did this yourself during/after the contest? Or maybe there’s a paper somewhere?) let me know!
Scoreboard Link to heading
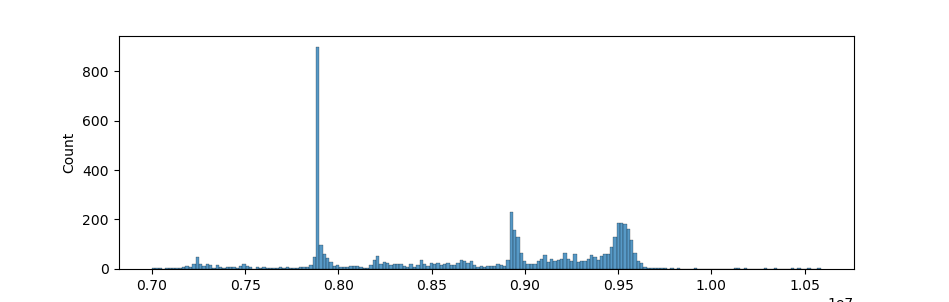
Figure 1: The scoreboard
When going over the scoreboard, some things draw attention: There’s a big peak around 7.9M. In fact, this peak is exactly at 7,885,741, the score of our first attempt: just set each traffic light to green for one second.
If you came up with the idea of filtering unused roads first, your score would jump up to the 8.9M peak.
For anybody in the top 1000, the peak from 9.4M to 9.6M will be all too well known:
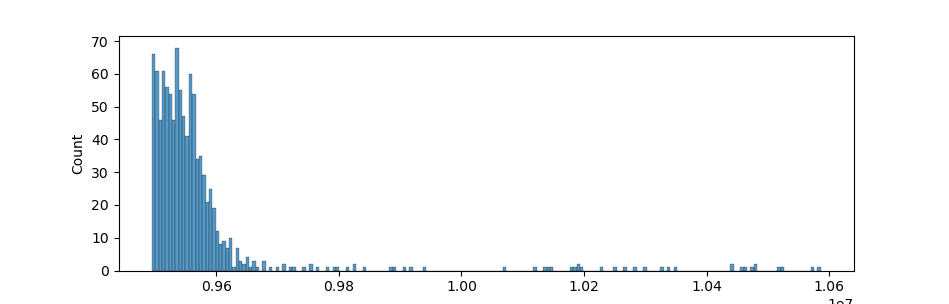
Figure 2: The top 1000 distribution
You could get to this range by using the idea of scaling green time by number of cars using a given street. Depending on how effective your approach/parameter search was, you would get more or less points. Also note that the peak here is much wider than the peaks at 7.9M and 8.9M.
Beyond this, you really didn’t need that many more points to get to the top 50: 9.7M was enough, and with a maximum score of 10.5M, there was plenty of headroom as well. The hard part was finding it.
There’s a bit of a gap around 10M, and some more points around 10.2M. I’m a bit surprised there’s so many teams between 9.8M and 10.2M actually - when we got the idea for D we jumped over this range, so there must be some other ideas out there that get intermediate points.
Looking at the top 10, we still had quite some headroom as well, but after the contest we identified most of our losses (80k on D, 200+k on F) and were able to reclaim some of it. As it stands now, we can schedule all cars to arrive in time, only apart from 39 cars that don’t make it in time in E, so that’s 19500 points of potential headroom.
I don’t know what strategies the other top 20 teams used to get this high - please let me know!
And thanks for reading my first blog here ;)