STPD: Compressing Suffix Trees by Path Decompositions
Text indexing: Locate all matches of a pattern Link to heading

Focus: Locate leftmost match of a pattern Link to heading

FM/r-index: cache miss per character Link to heading
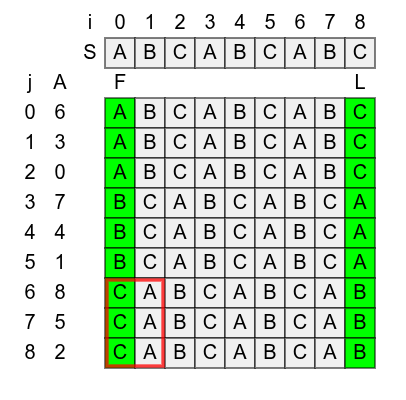
Suffix trees of repetitive text are repetitive too! Link to heading
Suffixient arrays, Cenzato+
Suffix tree: \(O(d + m/B + \mathit{occ})\) I/O complexity Link to heading
- \(m\): pattern length
- \(B\): block size
- \(d\): depth in suffix tree, usually small
- \(r\): runs in Burrows Wheeler Transform (BWT)
Goal: \(O( r)\) space, \(O(d+m/B+\mathit{occ})\) I/Os
STPD: \(O( r)\) space, \(O(d\color{red}{\cdot \log m}+m/B+\mathit{occ})\) I/Os

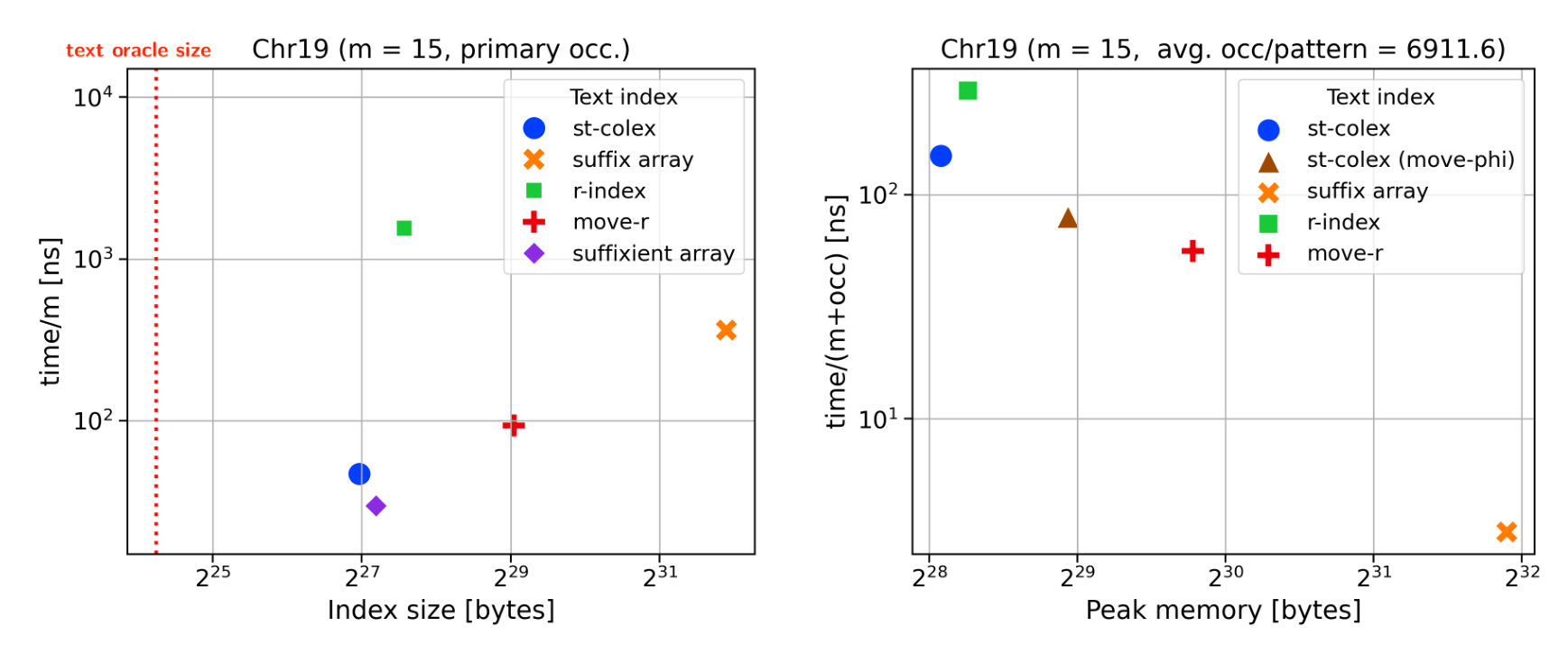
Results: Small & fast (\(m=15\)) Link to heading
Locate one 19x chr19 Locate all
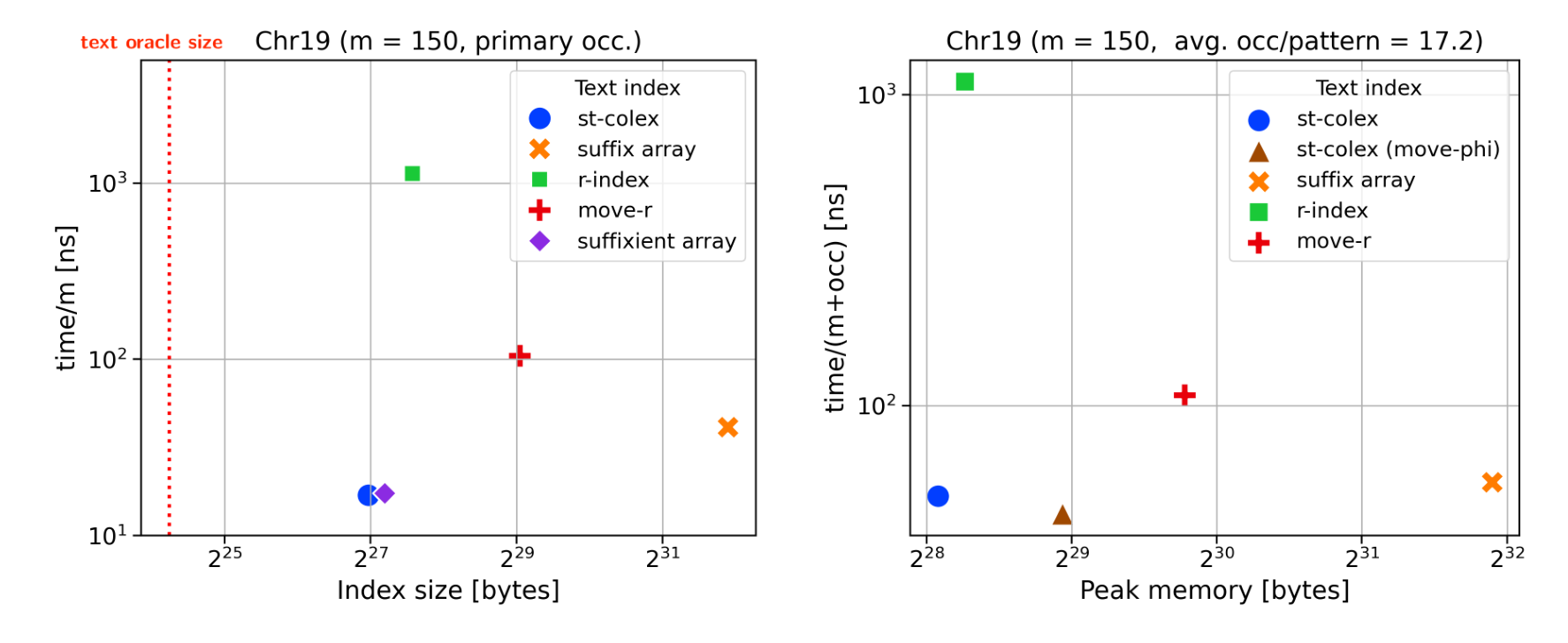
Results: Small & fast (\(m=150\)) Link to heading
Locate one 19x chr19 Locate all
Stringology time! Link to heading
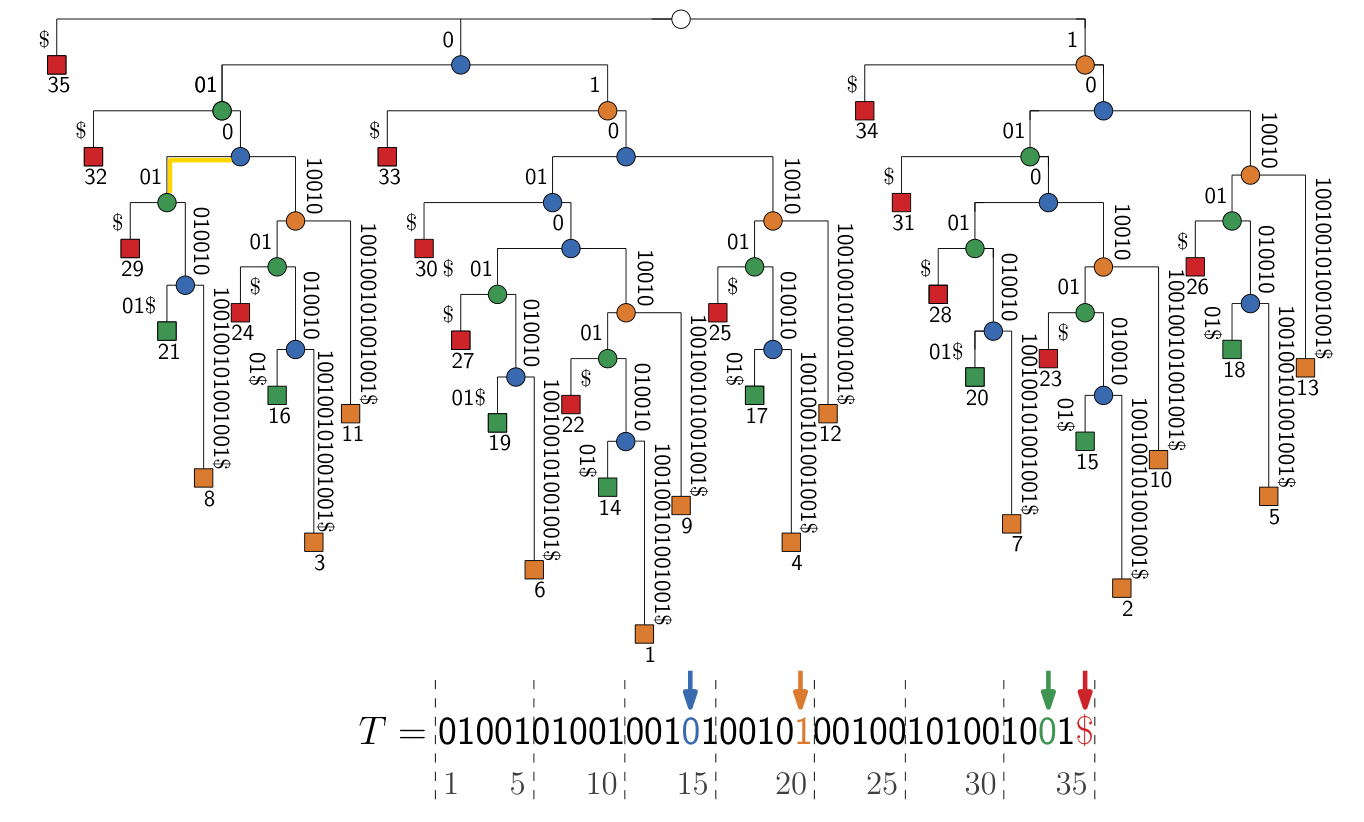
Substring x for which at least two extensions xA and xB exist in \(T\).
Aka: suffix-tree nodes.

Stringology time! Link to heading
Substring x for which at least two extensions xA and xB exist in \(T\).
Aka: suffix-tree nodes.
Extension xA of an RMS x.
Aka: suffix-tree edges.

Suffixient set Link to heading
A set of text positions \(S\) sorted in co-lex order, such that for each RME xA, there is \(i\in S\) s.t.
\(T[.. i)\) ends in xA.
\(|S|\leq 2r\) is possible. Note that access to the (compressed) text is needed.

Suffixient set queries Link to heading
Start greedily matching at start of \(T\). Say that prefix \(P[..j)\) of \(P\) matches.
If the extension \(P[..j]\) occurs in \(T\), it is an RME, and we can binary search a prefix from \(S\) that ends in it. Jump there and repeat.

Suffixient set queries Link to heading
Start greedily matching at start of \(T\). Say that prefix \(P[..j)\) of \(P\) matches.
If the extension \(P[..j]\) occurs in \(T\), it is an RME, and we can binary search a prefix from \(S\) that ends in it. Jump there and repeat.

Suffixient set queries Link to heading
Start greedily matching at start of \(T\). Say that prefix \(P[..j)\) of \(P\) matches.
If the extension \(P[..j]\) occurs in \(T\), it is an RME, and we can binary search a prefix from \(S\) that ends in it. Jump there and repeat.

Suffixient set queries Link to heading
Start greedily matching at start of \(T\). Say that prefix \(P[..j)\) of \(P\) matches.
If the extension \(P[..j]\) occurs in \(T\), it is an RME, and we can binary search a prefix from \(S\) that ends in it. Jump there and repeat.

Suffixient set {#suffixient-set (repeat)} Link to heading
A set of text positions \(S\) sorted in co-lex order, such that for each RME xA, there is \(i\in S\) s.t.
\(T[.. i)\) ends in xA.
Note that access to the (compressed) text is needed.
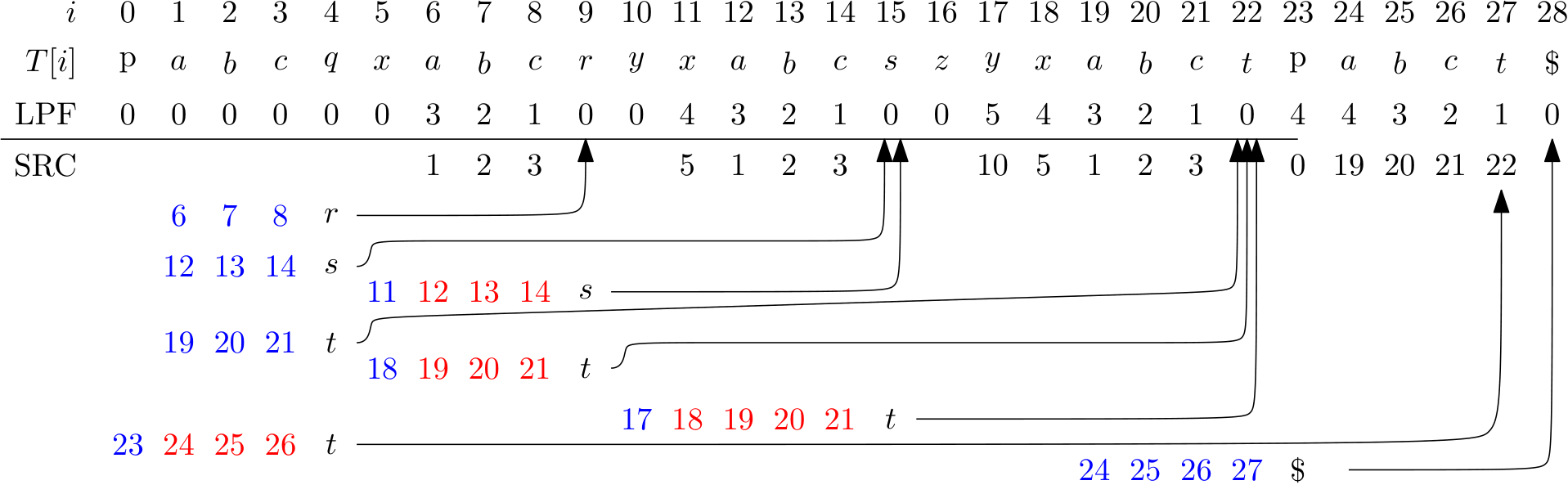
STPD Link to heading
The set of text positions \(S\), such that for each RME xA
that is not the lefmost occurrence of
x, there is \(i\in S\) s.t. \(T[.. i)\) is the lefmost occurrence of xA.

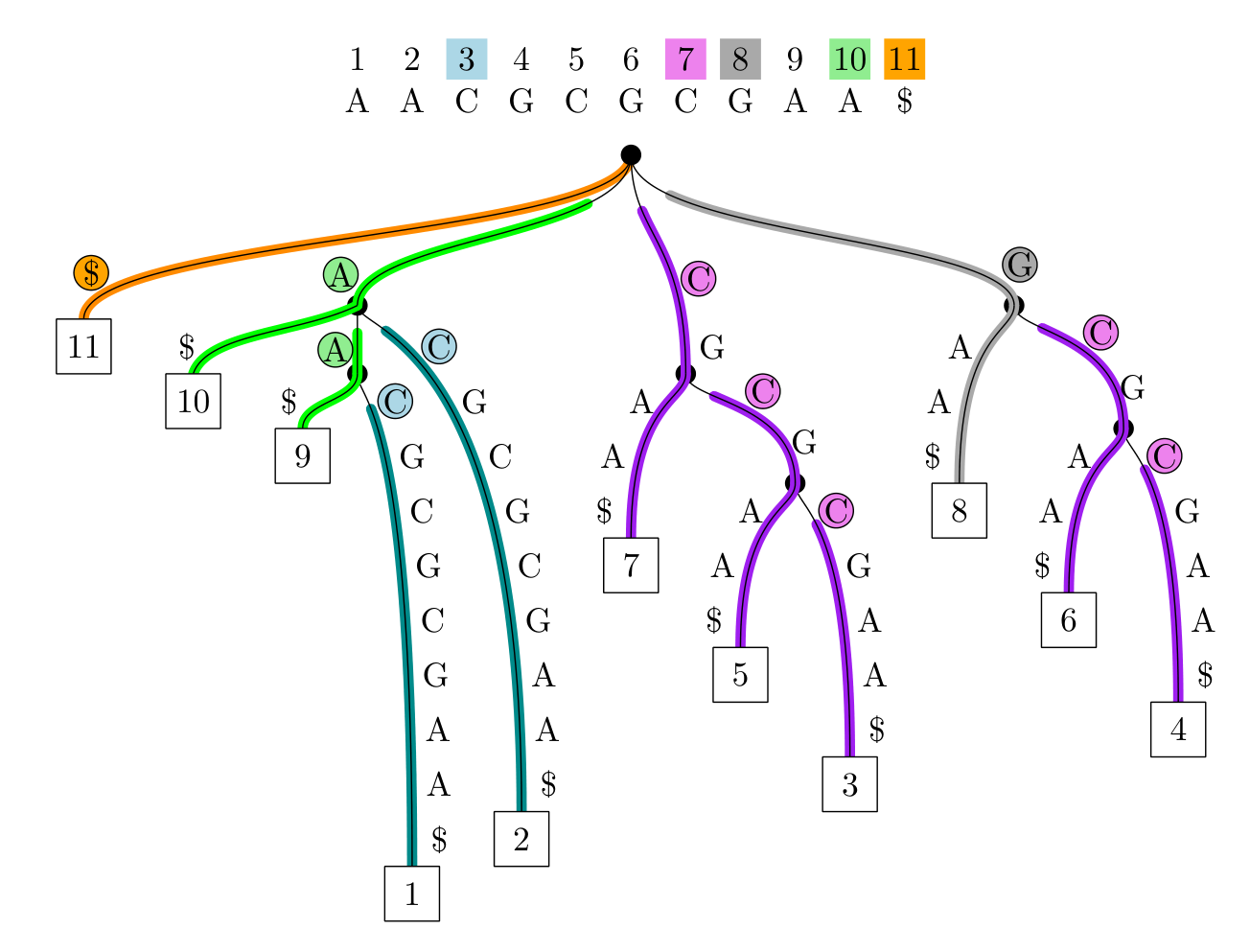
Larger lexicographic example Link to heading
Sizes on Pizza & Chili repetitive corpus Link to heading
| (in millions) | influenza | cere | escherichia |
|---|---|---|---|
| n | 155.0 | 461.0 | 112.0 |
| BWT runs \(r\) | 3.0 | 11.6 | 15.0 |
| suffixient set \(\chi\leq 2r\) | 2.2 | 9.9 | 13.1 |
| STPD: leftmost | 1.9 | 8.9 | 11.7 |
| STPD: lex min \(\leq r\) | 1.8 | 7.5 | 9.8 |
Conclusion Link to heading
- \(O( r)\) space alongside the text-oracle, in practice less than r-index
- Cache-friendly lookups, 30× faster than r-index
Outlook:
- Incremental construction, allowing to grow the text
- Direct pointer-based navigation on the text works great too???
Pointers Link to heading